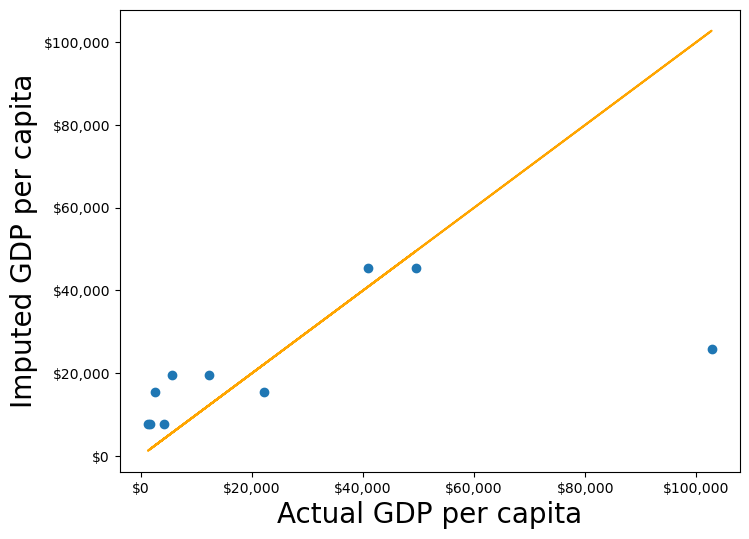
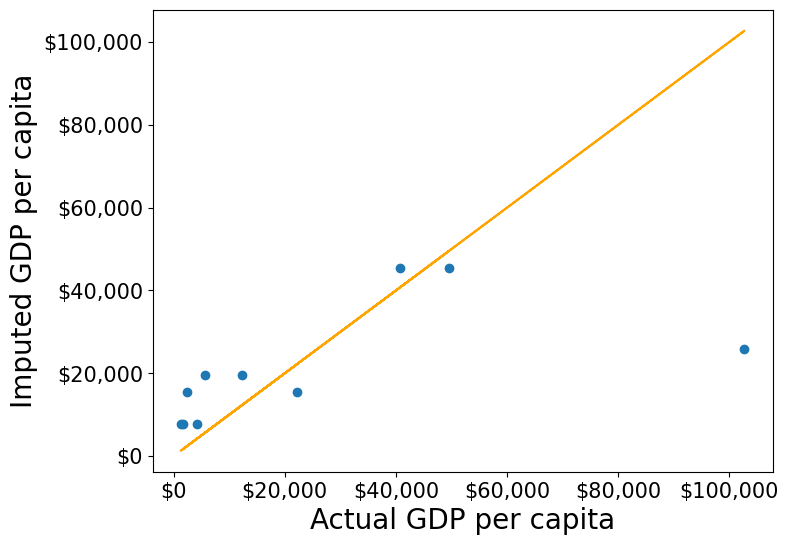
This chapter will consist of solutions suggested by students of the STAT303-1 Fall 2022 & Fall 2023 class, which are more efficient than those presented in the original version of the book.
10.1 Missing value imputation based on correlated variables in the data
The code below refers to Section 7.1.5.3 of the book. Students have proposed some ways to avoid a for loop in the code, which will lead to parallel computations, thereby saving execution time.
10.1.1 Original code
start_time = tm.time()gdp_imputed_data = gdp_missing_values_data.copy()for cont in avg_gdpPerCapita.index: gdp_imputed_data.loc[(gdp_imputed_data.continent==cont) & (gdp_imputed_data.gdpPerCapita.isnull()),'gdpPerCapita']=avg_gdpPerCapita[cont]plot_actual_vs_predicted()print("Time taken to execute code: ",np.round(tm.time()-start_time,3), "seconds")
RMSE= 25473.20645170116
Time taken to execute code: 0.061 seconds
Below are some more efficient ways to impute the missing values, as they avoid using the for loop.
10.1.2 Alternative code 1:
By Ryan Yi
start_time = tm.time()gdp_imputed_data = gdp_missing_values_data.copy()gdp_imputed_data.gdpPerCapita =\gdp_imputed_data['gdpPerCapita'].fillna(gdp_imputed_data['continent'].map(avg_gdpPerCapita))plot_actual_vs_predicted()print("Time taken to execute code: ",np.round(tm.time()-start_time,3), "seconds")
RMSE= 25473.20645170116
Time taken to execute code: 0.023 seconds
10.1.3 Alternative code 2:
By Victoria Shi
start_time = tm.time()gdp_imputed_data = gdp_missing_values_data.copy()gdp_imputed_data["gdpPerCapita"] = gdp_missing_values_data[['continent','gdpPerCapita']].groupby('continent').transform(lambda x: x.fillna(x.mean()))plot_actual_vs_predicted()print("Time taken to execute code: ",np.round(tm.time()-start_time,3), "seconds")
RMSE= 25473.20645170116
Time taken to execute code: 0.026 seconds
10.1.4 Alternative code 3:
By Elijah Nacar
start_time = tm.time()gdp_imputed_data = gdp_missing_values_data.copy()gdp_imputed_data.gdpPerCapita = gdp_imputed_data.apply(lambda x: avg_gdpPerCapita[x['continent']] if pd.isnull(x['gdpPerCapita']) else x['gdpPerCapita'],axis=1)plot_actual_vs_predicted()print("Time taken to execute code: ",np.round(tm.time()-start_time,3), "seconds")
RMSE= 25473.20645170116
Time taken to execute code: 0.023 seconds
RMSE= 25473.20645170116
Time taken to execute code: 0.022 seconds
10.2 Binning with equal sized bins
The code below refers to Section 7.2.2 of the book. A student has proposed a way to avoid the for loop in the code, which will lead to parallel computations, thereby saving execution time.
10.2.1 Original code (in the book)
#Bootstrapping to find 95% confidence intervals of Graduation Rate of US universities based on average expenditure per studentstart_time = tm.time()for expend_bin in college.Expend_bin.unique(): data_sub = college.loc[college.Expend_bin==expend_bin,:] samples = np.random.choice(data_sub['Grad.Rate'], size=(10000,data_sub.shape[0]))print("95% Confidence interval of Grad.Rate for "+expend_bin+" univeristies = ["+str(np.round(np.percentile(samples.mean(axis=1),2.5),2))+","+str(np.round(np.percentile(samples.mean(axis=1),97.5),2))+"]")print("Time taken to execute code: ",np.round(tm.time()-start_time,3), "seconds")
95% Confidence interval of Grad.Rate for Low expend univeristies = [55.31,59.35]
95% Confidence interval of Grad.Rate for High expend univeristies = [71.03,74.9]
95% Confidence interval of Grad.Rate for Med expend univeristies = [64.17,67.95]
Time taken to execute code: 0.151 seconds
10.2.2 Alternative code:
By Victoria Shi
start_time = tm.time()def confidence_interval(df): samples = np.random.choice(df['Grad.Rate'], size=(10000, df.shape[0]))print("95% Confidence interval of Grad.Rate for "+df["Expend_bin"].iloc[0]+" univeristies = ["+str(np.round(np.percentile(samples.mean(axis=1),2.5),2))+","+str(np.round(np.percentile(samples.mean(axis=1),97.5),2))+"]")college.groupby('Expend_bin').apply(confidence_interval)print("Time taken to execute code: ",np.round(tm.time()-start_time,3), "seconds")
95% Confidence interval of Grad.Rate for Low expend univeristies = [55.35,59.35]
95% Confidence interval of Grad.Rate for Med expend univeristies = [64.16,67.95]
95% Confidence interval of Grad.Rate for High expend univeristies = [71.05,74.96]
Time taken to execute code: 0.139 seconds