4 NumPy
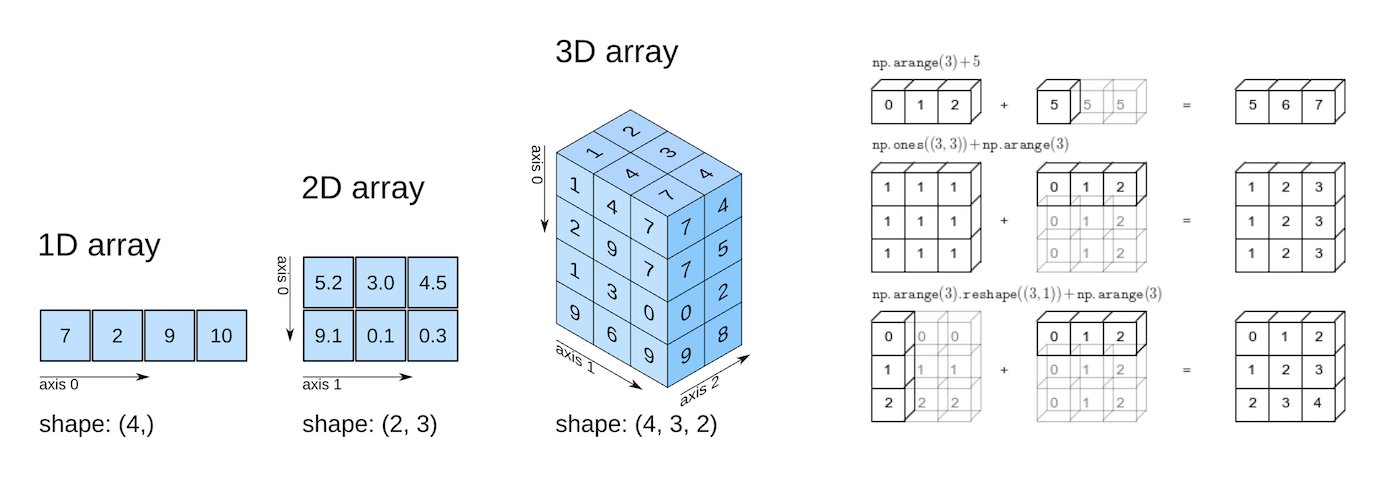
NumPy, short for Numerical Python is used to analyze numeric data with Python. NumPy arrays are primarily used to create homogeneous \(n\)-dimensional arrays (\(n = 1,...,n\)). Let us import the NumPy library to use its methods and functions, and the NumPy function array() to define a NumPy array.
import numpy as np#Using the NumPy function array() to define a NumPy array
numpy_array = np.array([[1,2],[3,4]])
numpy_arrayarray([[1, 2],
[3, 4]])type(numpy_array)numpy.ndarrayThe NumPy function array() creates an object of type numpy.ndarray.
4.1 Why do we need NumPy arrays?
NumPy arrays can store data just like other data structures such as such as lists, tuples, and Pandas DataFrame. Computations performed using NumPy arrays can also be performed with data stored in the other data structures. However, NumPy is preferred for its efficiency, especially when working with large arrays of data.
4.1.1 Numpy arrays are memory efficient
A NumPy array is a collection of homogeneous data-types that are stored in contiguous memory locations. On the other hand, data structures such as lists are a collection of heterogeneous data types stored in non-contiguous memory locations. Homogenous data elements let the NumPy array be densely packed resulting in lesser memory consumption. The following example illustrates the smaller size of NumPy arrays as compared to other data structures.
#Example showing NumPy arrays take less storage space than lists, tuples and Pandas DataFrame for the same elements
tuple_ex = tuple(range(1000))
list_ex = list(range(1000))
numpy_ex = np.array([range(1000)])
pandas_df = pd.DataFrame(range(1000))
print("Space taken by tuple =",tuple_ex.__sizeof__()," bytes")
print("Space taken by list =",list_ex.__sizeof__()," bytes")
print("Space taken by Pandas DataFrame =",pandas_df.__sizeof__()," bytes")
print("Space taken by NumPy array =",numpy_ex.__sizeof__()," bytes")Space taken by tuple = 8024 bytes
Space taken by list = 8040 bytes
Space taken by Pandas DataFrame = 8128 bytes
Space taken by NumPy array = 4120 bytesNote that NumPy arrays are memory efficient as long as they are homogenous. They will lose the memory efficiency if they are used to store elements of multiple data types.
The example below compares the size of a homogenous NumPy array to that of a similar heterogenous NumPy array to illustrate the point.
numpy_homogenous = np.array([[1,2],[3,3]])
print("Size of a homogenous numpy array = ",numpy_homogenous.__sizeof__(), "bytes")Size of homogenous numpy array = 136 bytesNow let us convert an element of the above array to a string, and check the size of the array.
numpy_homogenous = np.array([[1,'2'],[3,3]])
print("Size of a heterogenous numpy array = ",numpy_homogenous.__sizeof__(), "bytes")Size of a heterogenous numpy array = 296 bytesThe size of the homogenous NumPy array is much lesser than that of the one with heterogenous data. Thus, NumPy arrays are primarily used for storing homogenous data.
On the other hand, the size of other data structures, such as a list, does not depend on whether the elements in them are homogenous or heterogenous, as shown by the example below.
list_homogenous = list([1,2,3,4])
print("Size of a homogenous list = ",list_homogenous.__sizeof__(), "bytes")
list_heterogenous = list([1,'2',3,4])
print("Size of a heterogenous list = ",list_heterogenous.__sizeof__(), "bytes")Size of a homogenous list = 72 bytes
Size of a heterogenous list = 72 bytesNote that the memory efficiency of NumPy arrays does not come into play with a very small amount of data. Thus, a list with four elements - 1,2,3 and 4, has a lesser size than a NumPy array with the same elements. However, with larger datasets, such as the one shown earlier (sequence of integers from 0 to 999), the memory efficiency of NumPy arrays can be seen.
Unlike data structures such as lists, tuples, and dictionary, all elements of a NumPy array should be of same type to leverage the memory efficiency of NumPy arrays.
4.1.2 NumPy arrays are fast
With NumPy arrays, mathematical computations can be performed faster, as compared to other data structures, due to the following reasons:
As the NumPy array is densely packed with homogenous data, it helps retrieve the data faster as well, thereby making computations faster.
With NumPy, vectorized computations can replace the relatively more expensive python
forloops. The NumPy package breaks down the vectorized computations into multiple fragments and then processes all the fragments parallelly. However, with aforloop, computations will be one at a time.The NumPy package integrates C, and C++ codes in Python. These programming languages have very little execution time as compared to Python.
We’ll see the faster speed on NumPy computations in the example below.
Example: This example shows that computations using NumPy arrays are typically much faster than computations with other data structures.
Q: Multiply whole numbers upto 1 million by an integer, say 2. Compare the time taken for the computation if the numbers are stored in a NumPy array vs a list.
Use the numpy function arange() to define a one-dimensional NumPy array.
#Examples showing NumPy arrays are more efficient for numerical computation
import time as tm
start_time = tm.time()
list_ex = list(range(1000000)) #List containinig whole numbers upto 1 million
a=(list_ex*2)
print("Time take to multiply numbers in a list = ", tm.time()-start_time)
start_time = tm.time()
tuple_ex = tuple(range(1000000)) #Tuple containinig whole numbers upto 1 million
a=(tuple_ex*2)
print("Time take to multiply numbers in a tuple = ", tm.time()-start_time)
start_time = tm.time()
df_ex = pd.DataFrame(range(1000000)) #Pandas DataFrame containinig whole numbers upto 1 million
a=(df_ex*2)
print("Time take to multiply numbers in a Pandas DataFrame = ", tm.time()-start_time)
start_time = tm.time()
numpy_ex = np.arange(1000000) #NumPy array containinig whole numbers upto 1 million
a=(numpy_ex*2)
print("Time take to multiply numbers in a NumPy array = ", tm.time()-start_time)Time take to multiply numbers in a list = 0.023949384689331055
Time take to multiply numbers in a tuple = 0.03192734718322754
Time take to multiply numbers in a Pandas DataFrame = 0.047330617904663086
Time take to multiply numbers in a NumPy array = 0.04.2 NumPy array: Basic attributes
Let us define a NumPy array:
numpy_ex = np.array([[1,2,3],[4,5,6]])
numpy_exarray([[1, 2, 3],
[4, 5, 6]])The attributes of numpy_ex can be seen by typing numpy_ex followed by a ., and then pressing the tab key.
Some of the basic attributes of a NumPy array are the following:
4.2.1 ndim
Shows the number of dimensions (or axes) of the array.
numpy_ex.ndim24.2.2 shape
This is a tuple of integers indicating the size of the array in each dimension. For a matrix with n rows and m columns, the shape will be (n,m). The length of the shape tuple is therefore the rank, or the number of dimensions, ndim.
numpy_ex.shape(2, 3)4.2.3 size
This is the total number of elements of the array, which is the product of the elements of shape.
numpy_ex.size64.2.4 dtype
This is an object describing the type of the elements in the array. One can create or specify dtype’s using standard Python types. NumPy provides many, for example bool_, character, int_, int8, int16, int32, int64, float_, float8, float16, float32, float64, complex_, complex64, object_.
numpy_ex.dtypedtype('int32')4.2.5 T
This attribute is used to transpose the NumPy array. This is often used to make matrices (2-dimensional arrays) compatible for multiplication.
For matrix multiplication, the columns of the first matrix must be equal to the rows of the second matrix. For example, consider the matrix below:
matrix_to_multiply = np.array([[1,2,1],[0,1,0]])Suppose we wish to multiply this matrix with numpy_ex. Note the shape of both the matrices below.
matrix_to_multiply.shape(2, 3)numpy_ex.shape(2, 3)To multiply the above matrices the number of columns of the one of the matrices must be the same as the number of rows of the other matrix. With the current matrices, this is not true as the number of columns of the first matrix is 3, and the the number of rows of the second matrix is 2 (no matter which matrix is considered to be the first one).
However, if we transpose one of the matrices, their shapes will be compatible for multiplication. Let’s transpose matrix_to_multiply:
matrix_to_multiply_transpose = matrix_to_multiply.T
matrix_to_multiply_transposearray([[1, 0],
[2, 1],
[1, 0]])The shape of matrix_to_multiply_transpose is:
matrix_to_multiply_transpose.shape(3, 2)The matrices matrix_to_multiply_transpose and numpy_ex are compatible for matrix multiplication. However, the result will depend on the order in which the matrices are multiplied:
#Matrix multiplication with matrix_to_multiply_transpose before numpy_ex
matrix_to_multiply_transpose.dot(numpy_ex)array([[ 1, 2, 3],
[ 6, 9, 12],
[ 1, 2, 3]])#Matrix multiplication with numpy_ex before matrix_to_multiply_transpose
numpy_ex.dot(matrix_to_multiply_transpose)array([[ 8, 2],
[20, 5]])The shape of the resulting matrix is equal to the rows of the first matrix and the columns of the second matrix. The order of matrices must be decided as per the requirements of the problem.
4.3 Arithmetic operations
Numpy arrays support arithmetic operators like +, -, *, etc. We can perform an arithmetic operation on an array either with a single number (also called scalar) or with another array of the same shape. However, we cannot perform an arithmetic operation on an array with an array of a different shape.
Below are some examples of arithmetic operations on arrays.
#Defining two arrays of the same shape
arr1 = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 1, 2, 3]])
arr2 = np.array([[11, 12, 13, 14],
[15, 16, 17, 18],
[19, 11, 12, 13]])#Element-wise summation of arrays
arr1 + arr2array([[12, 14, 16, 18],
[20, 22, 24, 26],
[28, 12, 14, 16]])# Element-wise subtraction
arr2 - arr1array([[10, 10, 10, 10],
[10, 10, 10, 10],
[10, 10, 10, 10]])# Adding a scalar to an array adds the scalar to each element of the array
arr1 + 3array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 4, 5, 6]])# Dividing an array by a scalar divides all elements of the array by the scalar
arr1 / 2array([[0.5, 1. , 1.5, 2. ],
[2.5, 3. , 3.5, 4. ],
[4.5, 0.5, 1. , 1.5]])# Element-wise multiplication
arr1 * arr2array([[ 11, 24, 39, 56],
[ 75, 96, 119, 144],
[171, 11, 24, 39]])# Modulus operator with scalar
arr1 % 4array([[1, 2, 3, 0],
[1, 2, 3, 0],
[1, 1, 2, 3]], dtype=int32)4.4 Broadcasting
Broadcasting allows arithmetic operations between two arrays with different numbers of dimensions but compatible shapes.
The Broadcasting documentation succinctly explains it as the following:
“The term broadcasting describes how NumPy treats arrays with different shapes during arithmetic operations. Subject to certain constraints, the smaller array is broadcast across the larger array so that they have compatible shapes. Broadcasting provides a means of vectorizing array operations so that looping occurs in C instead of Python. It does this without making needless copies of data and usually leads to efficient algorithm implementations.”
The example below shows the broadcasting of two arrays.
arr1 = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 1, 2, 3]])
arr2 = np.array([4, 5, 6, 7])arr1 + arr2array([[ 5, 7, 9, 11],
[ 9, 11, 13, 15],
[13, 6, 8, 10]])When the expression arr1 + arr2 is evaluated, arr2 (which has the shape (4,)) is replicated three times to match the shape (3, 4) of arr1. Numpy performs the replication without actually creating three copies of the smaller dimension array, thus improving performance and using lower memory.
In the above addition of arrays, arr2 was stretched or broadcast to the shape of arr1. However, this broadcasting was possible only because the right dimension of both the arrays is 4, and the left dimension of one of the arrays is 1.
See the broadcasting documentation to understand the rules for broadcasting:
“When operating on two arrays, NumPy compares their shapes element-wise. It starts with the trailing (i.e. rightmost) dimensions and works its way left. Two dimensions are compatible when:
- they are equal, or
- one of them is 1”
If the rightmost dimension of arr2 is 3, broadcasting will not occur, as it is not equal to the rightmost dimension of arr1:
#Defining arr2 as an array of shape (3,)
arr2 = np.array([4, 5, 6])#Broadcasting will not happen when the broadcasting rules are violated
arr1 + arr2--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-24-d972d21b639e> in <module> ----> 1 arr1 + arr2 ValueError: operands could not be broadcast together with shapes (3,4) (3,)
4.5 Comparison
Numpy arrays support comparison operations like ==, !=, > etc. The result is an array of booleans.
arr1 = np.array([[1, 2, 3], [3, 4, 5]])
arr2 = np.array([[2, 2, 3], [1, 2, 5]])arr1 == arr2array([[False, True, True],
[False, False, True]])arr1 != arr2array([[ True, False, False],
[ True, True, False]])arr1 >= arr2array([[False, True, True],
[ True, True, True]])arr1 < arr2array([[ True, False, False],
[False, False, False]])Array comparison is frequently used to count the number of equal elements in two arrays using the sum method. Remember that True evaluates to 1 and False evaluates to 0 when booleans are used in arithmetic operations.
(arr1 == arr2).sum()34.6 Concatenating arrays
Arrays can be concatenated along an axis with NumPy’s concatenate function. The axis argument specifies the dimension for concatenation. The arrays should have the same number of dimensions, and the same length along each axis except the axis used for concatenation.
The examples below show concatenation of arrays.
arr1 = np.array([[1, 2, 3], [3, 4, 5]])
arr2 = np.array([[2, 2, 3], [1, 2, 5]])
print("Array 1:\n",arr1)
print("Array 2:\n",arr2)Array 1:
[[1 2 3]
[3 4 5]]
Array 2:
[[2 2 3]
[1 2 5]]#Concatenating the arrays along the default axis: axis=0
np.concatenate((arr1,arr2))array([[1, 2, 3],
[3, 4, 5],
[2, 2, 3],
[1, 2, 5]])#Concatenating the arrays along axis = 1
np.concatenate((arr1,arr2),axis=1)array([[1, 2, 3, 2, 2, 3],
[3, 4, 5, 1, 2, 5]])Since the arrays need to have the same dimension only along the axis of concatenation, let us try concatenate the array below (arr3) with arr1, along axis = 0.
arr3 = np.array([2, 2, 3])np.concatenate((arr1,arr3),axis=0)--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-43-33ac676c1fdf> in <module> ----> 1 np.concatenate((arr1,arr3),axis=0) <__array_function__ internals> in concatenate(*args, **kwargs) ValueError: all the input arrays must have same number of dimensions, but the array at index 0 has 2 dimension(s) and the array at index 1 has 1 dimension(s)
Note the above error, which indicates that arr3 has only one dimension. Let us check the shape of arr3.
arr3.shape(3,)We can reshape arr3 to a shape of (1,3) to make it compatible for concatenation with arr1 along axis = 0.
arr3_reshaped = arr3.reshape(1,3)
arr3_reshapedarray([[2, 2, 3]])Now we can concatenate the reshaped arr3 with arr1 along axis = 0.
np.concatenate((arr1,arr3_reshaped),axis=0)array([[1, 2, 3],
[3, 4, 5],
[2, 2, 3]])4.7 Practice exercise 1
4.7.0.1
Read the coordinates of the capital cities of the world from http://techslides.com/list-of-countries-and-capitals . Use NumPy to print the name and coordinates of the capital city closest to the US capital - Washington DC.
Note that:
- The Country Name for US is given as United States in the data.
- The ‘closeness’ of capital cities from the US capital is based on the Euclidean distance of their coordinates to those of the US capital.
Hints:
- Use read_html() from the Pandas library to read the table.
- Use the to_numpy() function of the Pandas DataFrame class to convert a DataFrame to a Numpy array
- Use broadcasting to compute the euclidean distance of capital cities from Washington DC.
Solution:
import pandas as pd
capital_cities = pd.read_html('http://techslides.com/list-of-countries-and-capitals',header=0)[0]
coordinates_capital_cities = capital_cities.iloc[:,2:4].to_numpy()
us_coordinates = capital_cities.loc[capital_cities['Country Name']=='United States',['Capital Latitude','Capital Longitude']].to_numpy()
#Broadcasting
distance_from_DC = np.sqrt(np.sum((us_coordinates-coordinates_capital_cities)**2,axis=1))
#Assigning a high value of distance to DC, otherwise it will itself be selected as being closest to DC
distance_from_DC[distance_from_DC==0]=9999
closest_capital_index = np.argmin(distance_from_DC)
print("Closest capital city is:" ,capital_cities.loc[closest_capital_index,'Capital Name'])
print("Coordinates of the closest capital city are:",coordinates_capital_cities[closest_capital_index,:])Closest capital city is: Ottawa
Coordinates of the closest capital city are: [ 45.41666667 -75.7 ]4.7.0.2
Use NumPy to:
Print the names of the countries of the top 10 capital cities closest to the US capital - Washington DC.
Create and print a NumPy array containing the coordinates of the top 10 cities.
Hint: Use the concatenate() function from the NumPy library to stack the coordinates of the top 10 cities.
top10_cities_coordinates = coordinates_capital_cities[closest_capital_index,:].reshape(1,2)
print("Top 10 countries closest to Washington DC are:\n Canada")
for i in range(9):
distance_from_DC[closest_capital_index]=9999
closest_capital_index = np.argmin(distance_from_DC)
print(capital_cities.loc[closest_capital_index,'Country Name'])
top10_cities_coordinates=np.concatenate((top10_cities_coordinates,coordinates_capital_cities[closest_capital_index,:].reshape(1,2)))
print("Coordinates of the top 10 cities closest to US are: \n",top10_cities_coordinates)Top 10 countries closest to Washington DC are:
Canada
Bahamas
Bermuda
Cuba
Turks and Caicos Islands
Cayman Islands
Haiti
Jamaica
Dominican Republic
Saint Pierre and Miquelon
Coordinates of the top 10 cities closest to US are:
[[ 45.41666667 -75.7 ]
[ 25.08333333 -77.35 ]
[ 32.28333333 -64.783333 ]
[ 23.11666667 -82.35 ]
[ 21.46666667 -71.133333 ]
[ 19.3 -81.383333 ]
[ 18.53333333 -72.333333 ]
[ 18. -76.8 ]
[ 18.46666667 -69.9 ]
[ 46.76666667 -56.183333 ]]4.8 Vectorized computation with NumPy
Several matrix algebra operations such as multiplications, decompositions, determinants, etc. can be performed conveniently with NumPy. However, we’ll focus on matrix multiplication as it is very commonly used to avoid python for loops and make computations faster. The dot function is used to multiply matrices:
#Defining a 2x2 matrix
a = np.array([[0,1],[3,4]])
aarray([[0, 1],
[3, 4]])#Defining a 2x2 matrix
b = np.array([[6,-1],[2,1]])
barray([[ 6, -1],
[ 2, 1]])#Multiplying matrices 'a' and 'b' using the dot function
a.dot(b)array([[ 2, 1],
[26, 1]])#Note that * results in element-wise multiplication
a*barray([[ 0, -1],
[ 6, 4]])Example 2: This example will show vectorized computations with NumPy. Vectorized computations help perform computations more efficiently, and also make the code concise.
Q: Read the (1) quantities of roll, bun, cake and bread required by 3 people - Ben, Barbara & Beth, from food_quantity.csv, (2) price of these food items in two shops - Target and Kroger, from price.csv. Find out which shop should each person go to minimize their expenses.
#Reading the datasets on food quantity and price
import pandas as pd
food_qty = pd.read_csv('./Datasets/food_quantity.csv')
price = pd.read_csv('./Datasets/price.csv')food_qty| Person | roll | bun | cake | bread | |
|---|---|---|---|---|---|
| 0 | Ben | 6 | 5 | 3 | 1 |
| 1 | Barbara | 3 | 6 | 2 | 2 |
| 2 | Beth | 3 | 4 | 3 | 1 |
price| Item | Target | Kroger | |
|---|---|---|---|
| 0 | roll | 1.5 | 1.0 |
| 1 | bun | 2.0 | 2.5 |
| 2 | cake | 5.0 | 4.5 |
| 3 | bread | 16.0 | 17.0 |
First, let’s start from a simple problem. We’ll compute the expenses of Ben if he prefers to buy all food items from Target
#Method 1: Using loop
bens_target_expense = 0 #Initializing Ben's expenses to 0
for k in range(4): #Iterating over all the four desired food items
bens_target_expense += food_qty.iloc[0,k+1]*price.iloc[k,1] #Total expenses on the kth item
bens_target_expense #Total expenses for Ben if he goes to Target50.0#Method 2: Using NumPy array
food_num = food_qty.iloc[0,1:].to_numpy() #Converting food quantity (for Ben) dataframe to NumPy array
price_num = price.iloc[:,1].to_numpy() #Converting price (for Target) dataframe to NumPy array
food_num.dot(price_num) #Matrix multiplication of the quantity vector with the price vector directly yields the result50.0Ben will spend $50 if he goes to Target
Now, let’s add another layer of complication. We’ll compute Ben’s expenses for both stores - Target and Kroger
#Method 1: Using loops
#Initializing a Series of length two to store the expenses in Target and Kroger for Ben
bens_store_expense = pd.Series(0.0,index=price.columns[1:3])
for j in range(2): #Iterating over both the stores - Target and Kroger
for k in range(4): #Iterating over all the four desired food items
bens_store_expense[j] += food_qty.iloc[0,k+1]*price.iloc[k,j+1]
bens_store_expenseTarget 50.0
Kroger 49.0
dtype: float64#Method 2: Using NumPy array
food_num = food_qty.iloc[0,1:].to_numpy() #Converting food quantity (for Ben) dataframe to NumPy array
price_num = price.iloc[:,1:].to_numpy() #Converting price dataframe to NumPy array
food_num.dot(price_num) #Matrix multiplication of the quantity vector with the price matrix directly yields the resultarray([50.0, 49.0], dtype=object)Ben will spend \$50 if he goes to Target, and $49 if he goes to Kroger. Thus, he should choose Kroger.
Now, let’s add the final layer of complication, and solve the problem. We’ll compute everyone’s expenses for both stores - Target and Kroger
#Method 1: Using loops
store_expense = pd.DataFrame(0.0,index=price.columns[1:3],columns = food_qty['Person'])
for i in range(3): #Iterating over all the three people - Ben, Barbara, and Beth
for j in range(2): #Iterating over both the stores - Target and Kroger
for k in range(4): #Iterating over all the four desired food items
store_expense.iloc[j,i] += food_qty.iloc[i,k+1]*price.iloc[k,j+1]
store_expense| Person | Ben | Barbara | Beth |
|---|---|---|---|
| Target | 50.0 | 58.5 | 43.5 |
| Kroger | 49.0 | 61.0 | 43.5 |
#Method 2: Using NumPy array
food_num = food_qty.iloc[:,1:].to_numpy() #Converting food quantity dataframe to NumPy array
price_num = price.iloc[:,1:].to_numpy() #Converting price dataframe to NumPy array
food_num.dot(price_num) #Matrix multiplication of the quantity matrix with the price matrix directly yields the resultarray([[50. , 49. ],
[58.5, 61. ],
[43.5, 43.5]])Based on the above table, Ben should go to Kroger, Barbara to Target and Beth can go to either store.
Note that, with each layer of complication, the number of for loops keep increasing, thereby increasing the complexity of Method 1, while the method with NumPy array does not change much. Vectorized computations with arrays are much more efficient.
4.8.1 Practice exercise 2
Use matrix multiplication to find the average IMDB rating and average Rotten tomatoes rating for each genre - comedy, action, drama and horror. Use the data: movies_cleaned.csv. Which is the most preferred genre for IMDB users, and which is the least preferred genre for Rotten Tomatoes users?
Hint: 1. Create two matrices - one containing the IMDB and Rotten Tomatoes ratings, and the other containing the genre flags (comedy/action/drama/horror).
Multiply the two matrices created in 1.
Divide each row/column of the resulting matrix by a vector having the number of ratings in each genre to get the average rating for the genre.
Solution:
import pandas as pd
data = pd.read_csv('./Datasets/movies_cleaned.csv')
data.head()| Title | IMDB Rating | Rotten Tomatoes Rating | Running Time min | Release Date | US Gross | Worldwide Gross | Production Budget | comedy | Action | drama | horror | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Broken Arrow | 5.8 | 55 | 108 | Feb 09 1996 | 70645997 | 148345997 | 65000000 | 0 | 1 | 0 | 0 |
| 1 | Brazil | 8.0 | 98 | 136 | Dec 18 1985 | 9929135 | 9929135 | 15000000 | 1 | 0 | 0 | 0 |
| 2 | The Cable Guy | 5.8 | 52 | 95 | Jun 14 1996 | 60240295 | 102825796 | 47000000 | 1 | 0 | 0 | 0 |
| 3 | Chain Reaction | 5.2 | 13 | 106 | Aug 02 1996 | 21226204 | 60209334 | 55000000 | 0 | 1 | 0 | 0 |
| 4 | Clash of the Titans | 5.9 | 65 | 108 | Jun 12 1981 | 30000000 | 30000000 | 15000000 | 0 | 1 | 0 | 0 |
# Getting ratings of all movies
drating = data[['IMDB Rating','Rotten Tomatoes Rating']]
drating_num = drating.to_numpy() #Converting the data to NumPy array
drating_numarray([[ 5.8, 55. ],
[ 8. , 98. ],
[ 5.8, 52. ],
...,
[ 7. , 65. ],
[ 5.7, 26. ],
[ 6.7, 82. ]])# Getting the matrix indicating the genre of all movies
dgenre = data.iloc[:,8:12]
dgenre_num = dgenre.to_numpy() #Converting the data to NumPy array
dgenre_numarray([[0, 1, 0, 0],
[1, 0, 0, 0],
[1, 0, 0, 0],
...,
[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 1, 0, 0]], dtype=int64)We’ll first find the total IMDB and Rotten tomatoes ratings for all movies of each genre, and then divide them by the number of movies of the corresponding genre to find the average rating for the genre.
For finding the total IMDB and Rotten tomatoes ratings, we’ll multiply drating_num with dgenre_num. However, before multiplying, we’ll check if their shapes are compatible for matrix multiplication.
#Shape of drating_num
drating_num.shape(980, 2)#Shape of dgenre_num
dgenre_num.shape(980, 4)Note that the above shapes are not compatible for matrix multiplication. We’ll transpose dgenre_num to make the shapes compatible.
#Total IMDB and Rotten tomatoes ratings for each genre
ratings_sum_genre = drating_num.T.dot(dgenre_num)
ratings_sum_genrearray([[ 1785.6, 1673.1, 1630.3, 946.2],
[14119. , 13725. , 14535. , 6533. ]])#Number of movies in the data will be stored in 'rows', and number of columns stored in 'cols'
rows, cols = data.shape#Getting number of movies in each genre
movies_count_genre = dgenre_num.T.dot(np.ones(rows))
movies_count_genrearray([302., 264., 239., 154.])#Finding the average IMDB and average Rotten tomatoes ratings for each genre
ratings_sum_genre/movies_count_genrearray([[ 5.91258278, 6.3375 , 6.82133891, 6.14415584],
[46.75165563, 51.98863636, 60.81589958, 42.42207792]])pd.DataFrame(ratings_sum_genre/movies_count_genre,columns = ['comedy','Action','drama','horror'],
index = ['IMDB Rating','Rotten Tomatoes Rating'])| comedy | Action | drama | horror | |
|---|---|---|---|---|
| IMDB Rating | 5.912583 | 6.337500 | 6.821339 | 6.144156 |
| Rotten Tomatoes Rating | 46.751656 | 51.988636 | 60.815900 | 42.422078 |
IMDB users prefer drama, and are amused the least by comedy movies, on an average. However, Rotten tomatoes critics would rather watch comedy than horror movies, on an average.
4.9 Pseudorandom number generation
Random numbers often need to be generated to analyze processes or systems, especially in cases when these processes or systems are governed by known probability distrbutions. For example, the number of personnel required to answer calls at a call center can be analyzed by simulating occurence and duration of calls.
NumPy’s random module can be used to generate arrays of random numbers from several different probability distributions. For example, a 3x5 array of uniformly distributed random numbers can be generated using the uniform function of the random module.
np.random.uniform(size = (3,5))array([[0.69256322, 0.69259973, 0.03515058, 0.45186048, 0.43513769],
[0.07373366, 0.07465425, 0.92195975, 0.72915895, 0.8906299 ],
[0.15816734, 0.88144978, 0.05954028, 0.81403832, 0.97725557]])Random numbers can also be generated by Python’s built-in random module. However, it generates one random number at a time, which makes it much slower than NumPy’s random module.
Example: Suppose 500 people eat at Food cart 1, and another 500 eat at Food cart 2, everyday.
The waiting time at Food cart 2 has a normal distribution with mean 8 minutes and standard deviation 3 minutes, while the waiting time at Food cart 1 has a uniform distribution with minimum 5 minutes and maximum 25 minutes.
Simulate a dataset containing waiting times for 500 ppl for 30 days in each of the food joints. Assume that the waiting times are measured simultaneously at a certain time in both places, i.e., the observations are paired.
On how many days is the average waiting time at Food cart 2 higher than that at Food cart 1?
What percentage of times the waiting time at Food cart 2 was higher than the waiting time at Food cart 1?
Try both approaches: (1) Using loops to generate data, (2) numpy array to generate data. Compare the time taken in both approaches.
import time as tm#Method 1: Using loops
start_time = tm.time() #Current system time
#Initializing waiting times for 500 ppl over 30 days
waiting_times_FoodCart1 = pd.DataFrame(0,index=range(500),columns=range(30)) #FoodCart1
waiting_times_FoodCart2 = pd.DataFrame(0,index=range(500),columns=range(30)) #FoodCart2
import random as rm
for i in range(500): #Iterating over 500 ppl
for j in range(30): #Iterating over 30 days
waiting_times_FoodCart2.iloc[i,j] = rm.gauss(8,3) #Simulating waiting time in FoodCart2 for the ith person on jth day
waiting_times_FoodCart1.iloc[i,j] = rm.uniform(5,25) #Simulating waiting time in FoodCart1 for the ith person on jth day
time_diff = waiting_times_FoodCart2-waiting_times_FoodCart1
print("On ",sum(time_diff.mean()>0)," days, the average waiting time at FoodCart2 higher than that at FoodCart1")
print("Percentage of times waiting time at FoodCart2 was greater than that at FoodCart1 = ",100*(time_diff>0).sum().sum()/(30*500),"%")
end_time = tm.time() #Current system time
print("Time taken = ", end_time-start_time)On 0 days, the average waiting time at FoodCart2 higher than that at FoodCart1
Percentage of times waiting time at FoodCart2 was greater than that at FoodCart1 = 16.226666666666667 %
Time taken = 4.521248817443848#Method 2: Using NumPy arrays
start_time = tm.time()
waiting_time_FoodCart2 = np.random.normal(8,3,size = (500,30)) #Simultaneously generating the waiting times of 500 ppl over 30 days in FoodCart2
waiting_time_FoodCart1 = np.random.uniform(5,25,size = (500,30)) #Simultaneously generating the waiting times of 500 ppl over 30 days in FoodCart1
time_diff = waiting_time_FoodCart2-waiting_time_FoodCart1
print("On ",(time_diff.mean()>0).sum()," days, the average waiting time at FoodCart2 higher than that at FoodCart1")
print("Percentage of times waiting time at FoodCart2 was greater than that at FoodCart1 = ",100*(time_diff>0).sum()/15000,"%")
end_time = tm.time()
print("Time taken = ", end_time-start_time)On 0 days, the average waiting time at FoodCart2 higher than that at FoodCart1
Percentage of times waiting time at FoodCart2 was greater than that at FoodCart1 = 16.52 %
Time taken = 0.008000850677490234The approach with NumPy is much faster than the one with loops.
4.9.1 Practice exercise 3
Bootstrapping: Find the 95% confidence interval of mean profit for ‘Action’ movies, using Bootstrapping.
Bootstrapping is a non-parametric method for obtaining confidence interval. Use the algorithm below to find the confidence interval:
- Find the profit for each of the ‘Action’ movies. Suppose there are N such movies. We will have a Profit column with N values.
- Randomly sample N values with replacement from the Profit column
- Find the mean of the N values obtained in (b)
- Repeat steps (b) and (c) M=1000 times
- The 95% Confidence interval is the range between the 2.5% and 97.5% percentile values of the 1000 means obtained in (c)
Use the movies_cleaned.csv dataset.
Solution:
#Reading data
movies = pd.read_csv('./Datasets/movies_cleaned.csv')
#Filtering action movies
movies_action = movies.loc[movies['Action']==1,:]
#Computing profit of movies
movies_action.loc[:,'Profit'] = movies_action.loc[:,'Worldwide Gross'] - movies_action.loc[:,'Production Budget']
#Subsetting the profit column
profit_vec = movies_action['Profit']
#Creating a matrix of 1000 samples with replacement from the profit column
bootstrap_samples=np.random.choice(profit_vec,size = (1000,len(profit_vec)))
#Computing the mean of each of the 1000 samples
bootstrap_sample_means = bootstrap_samples.mean(axis=1)
#The confidence interval is the 2.5th and 97.5th percentile of the mean of the 1000 samples
print("Confidence interval = [$"+str(np.round(np.percentile(bootstrap_sample_means,2.5)/1e6,2))+" million, $"+str(np.round(np.percentile(bootstrap_sample_means,97.5)/1e6,2))+" million]")Confidence interval = [$132.53 million, $182.69 million]